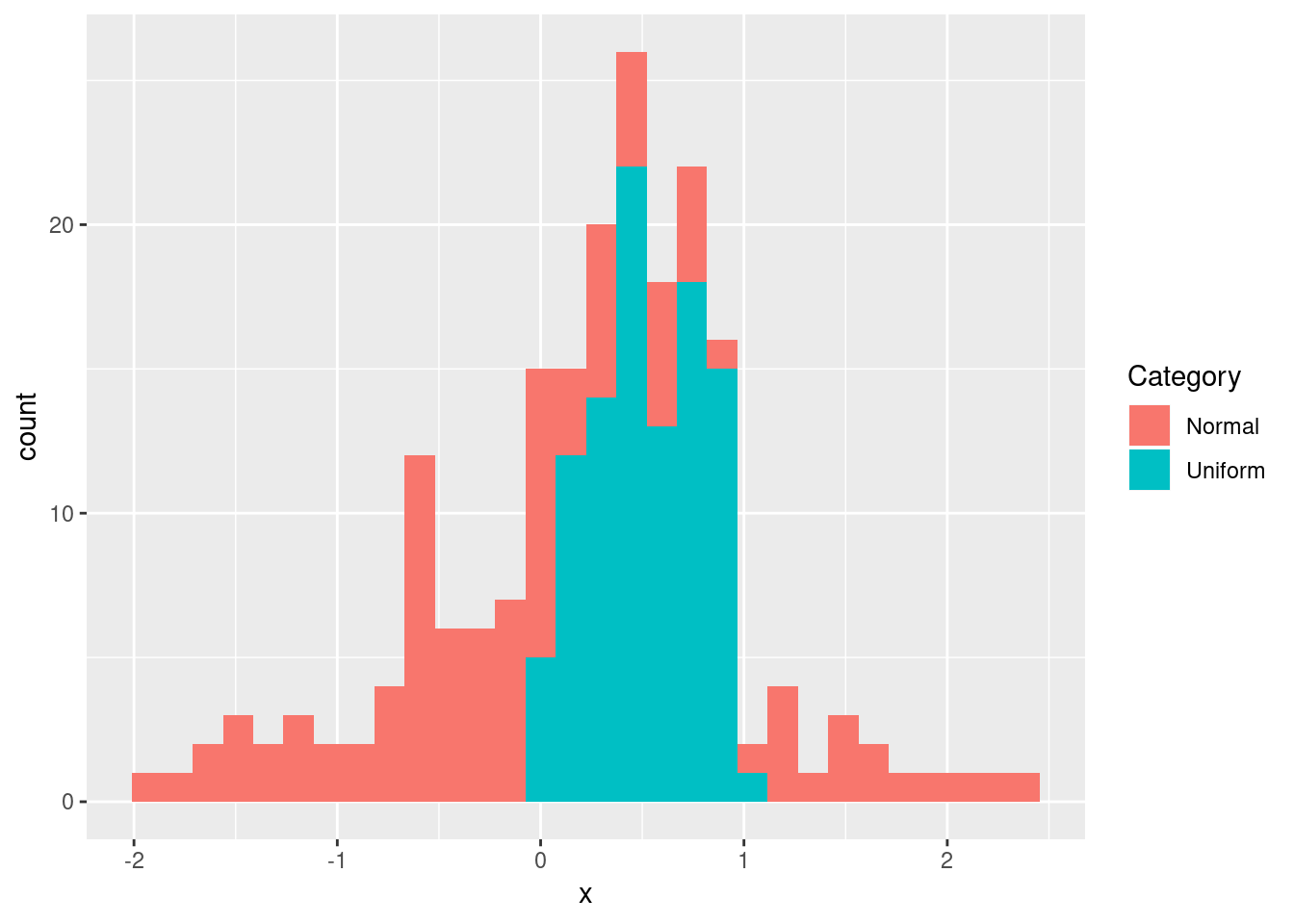
Determining the Distribution of Data Using Histograms
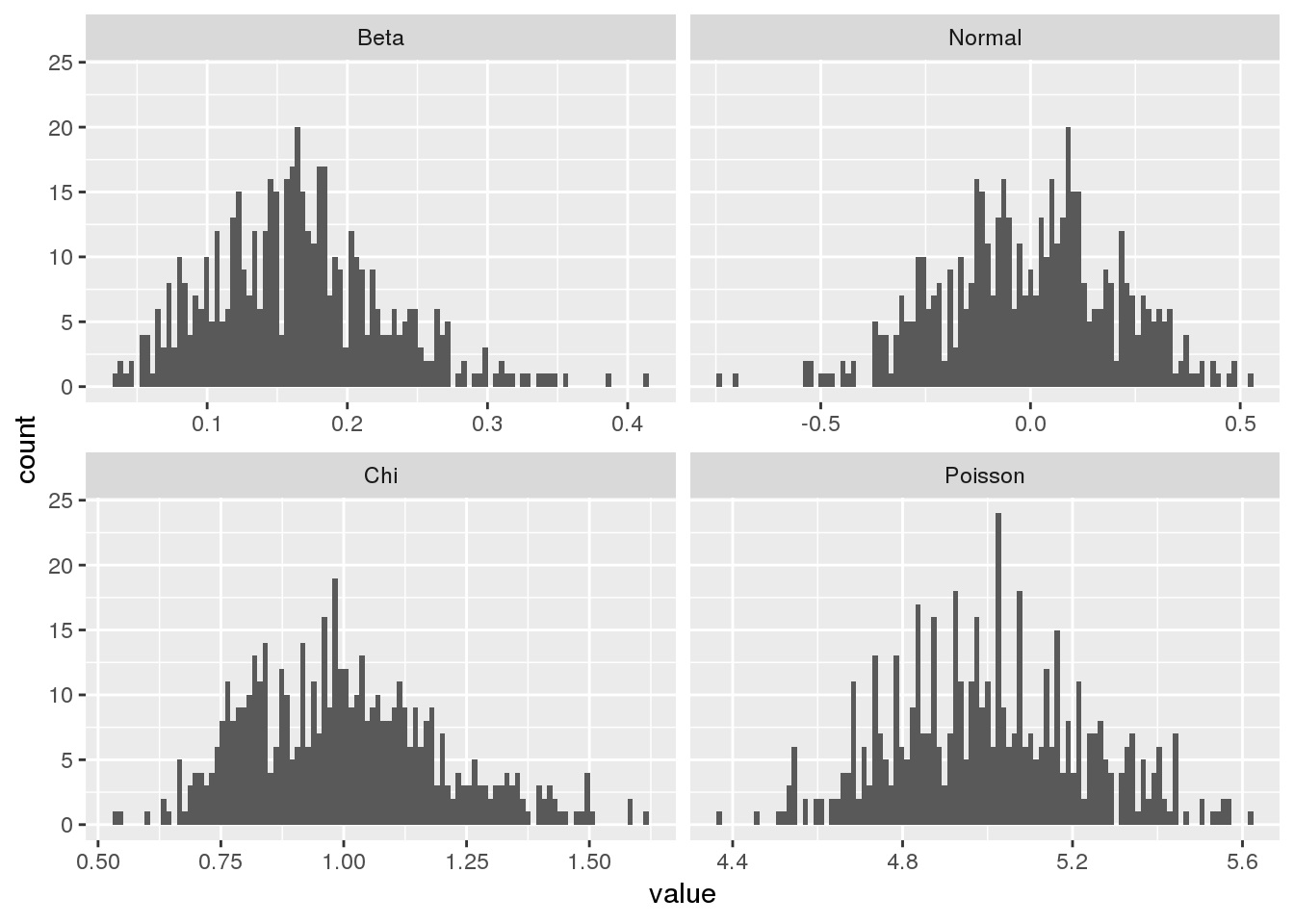
It is always useful to spend some time exploring a new data set before processing it further and analyzing it. One of the most convenient ways to get a feel for the data is plotting a histogram. The histogram is a tool for visualizing the frequency of measurements in terms of a bar plot. Here we’ll take a closer look at how the histogram can be used in R.



{kind=link}