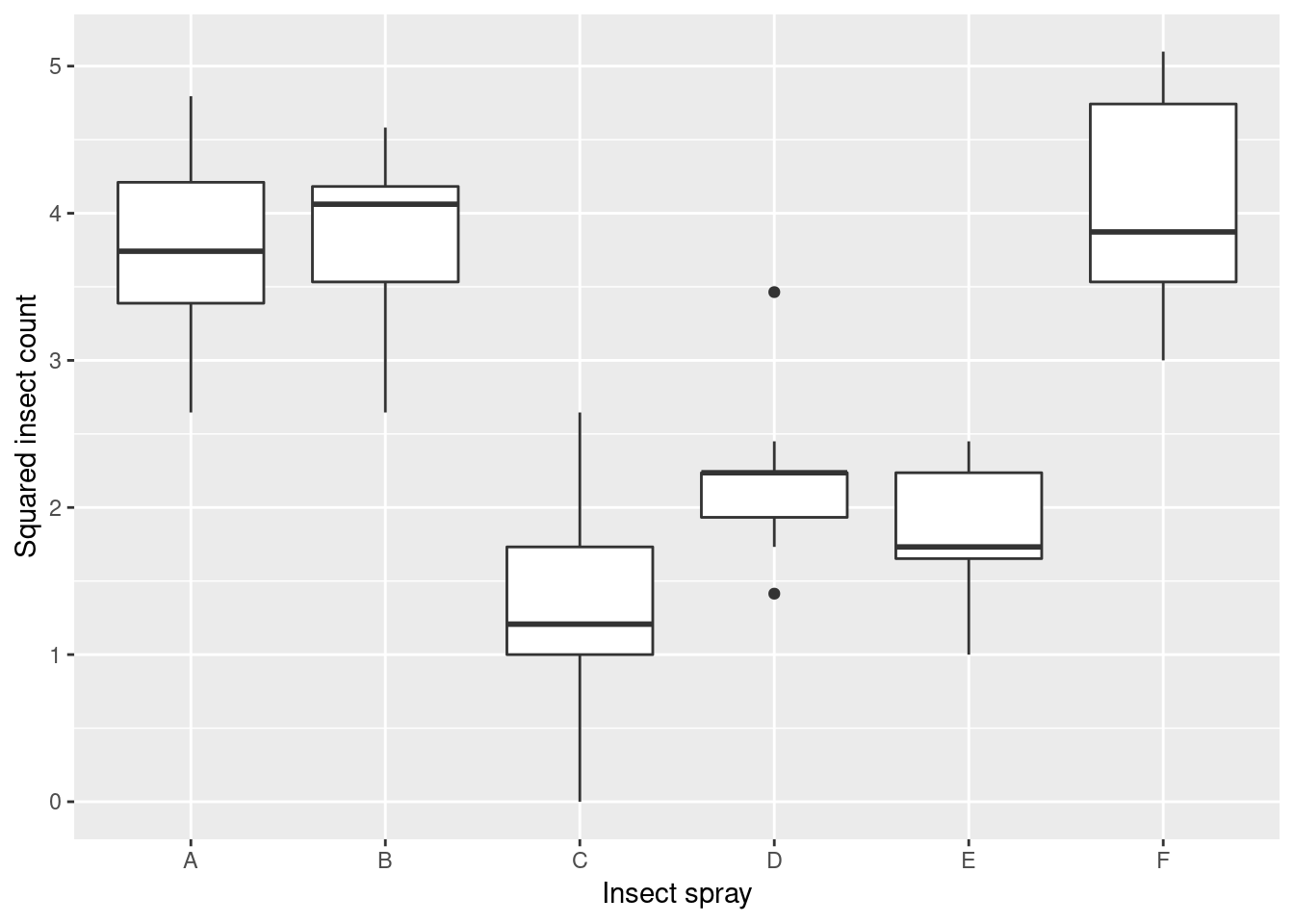
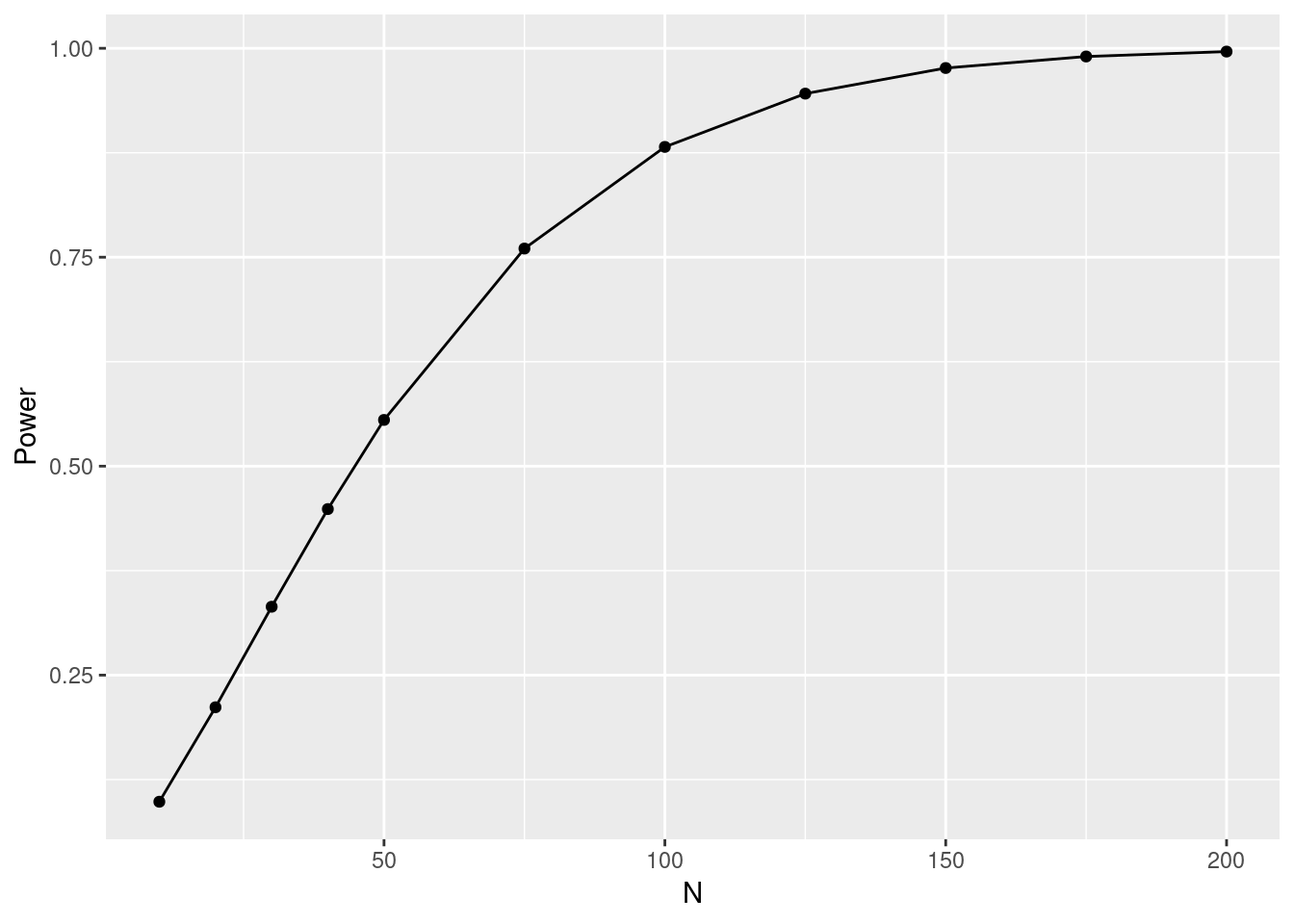
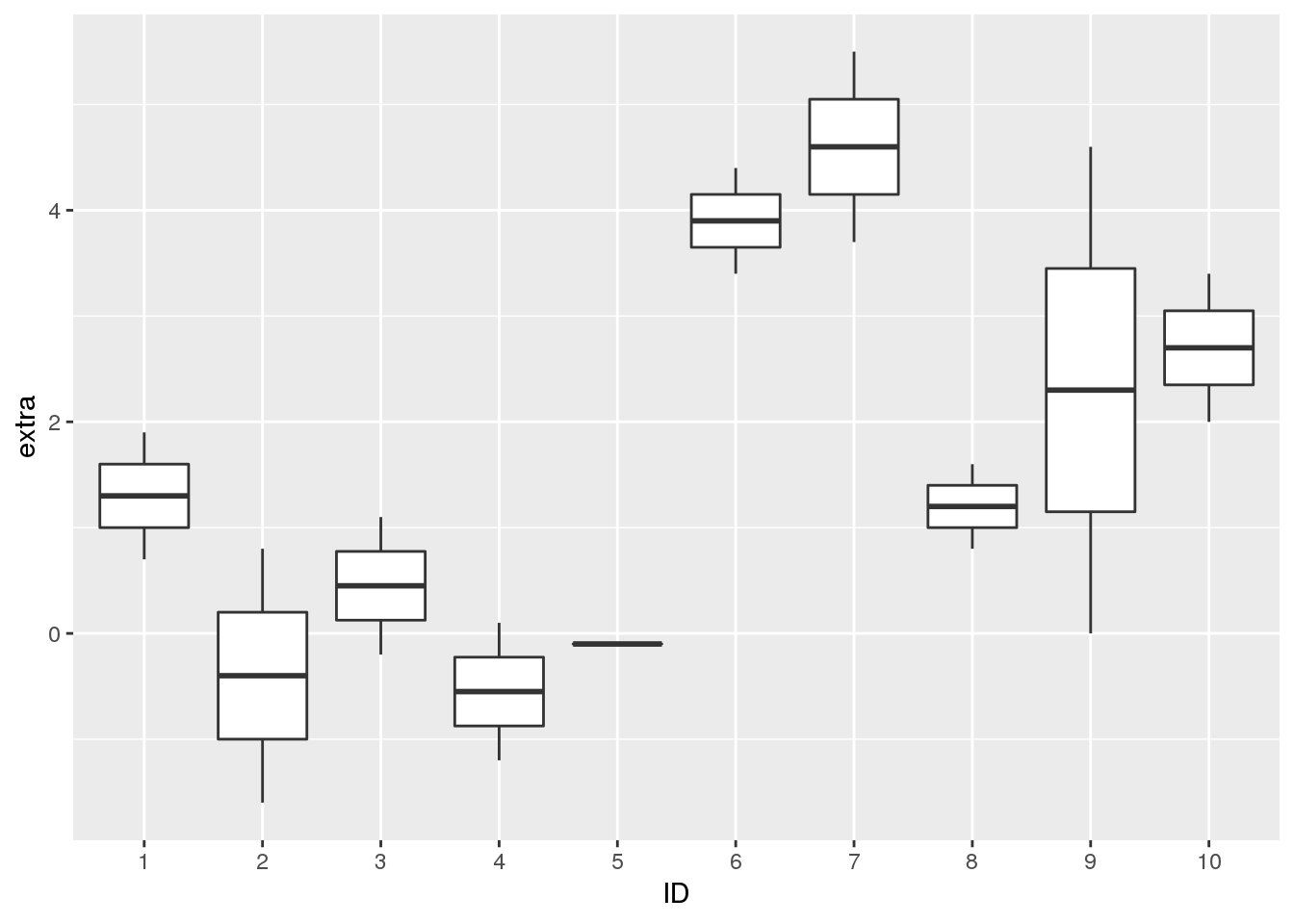
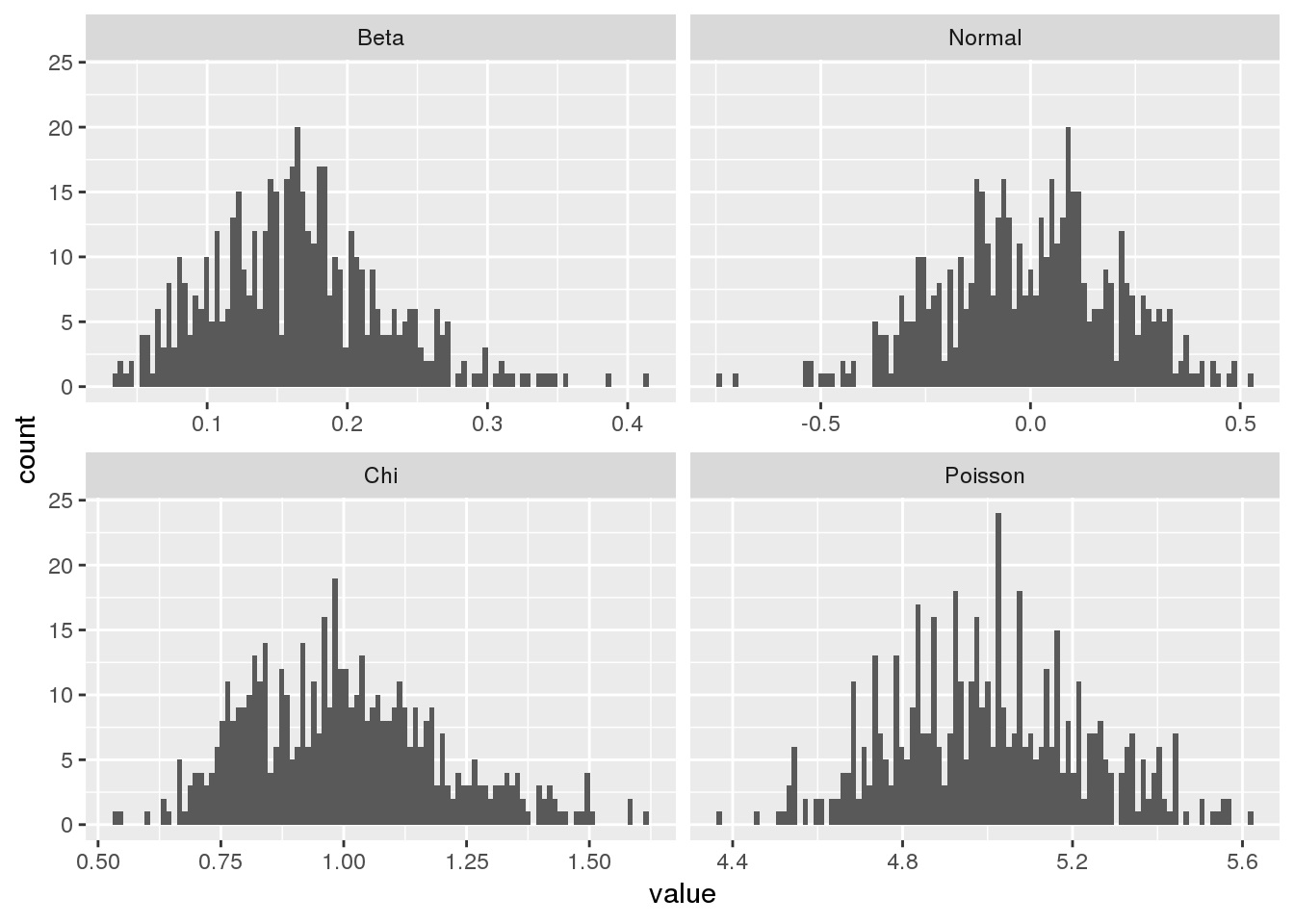
Using statistical tests, it is possible to make a statement about the significance of a set of measurements by calculating a test statistic. If it is unlikely to obtain a test statistic at least as extreme as the observed value, then the result is significant. For example, at a significance level of 5%, the probability of a false positive test result would be bounded by roughly 5%.
Parametric vs non-parametric tests
There is a multitude of tests for determining statistical significance. These tests can be differentiated into two categories: parametric and non-parametric tests. While parametric tests make assumptions on the distribution of the data, non-parametric tests do not rely on such assumptions. For example, the parametric t-test compares the means of two groups because it assumes that the data have a normal distribution.
The non-parametric Wilcoxon rank sum test (Mann-Whitney U test), on the other hand, considers the medians of the groups instead. If the assumptions of parametric tests are met, they are generally more capable of detecting an effect than non-parametric tests. If this is not the case, however, non-parametric tests should be preferred.
Choosing an appropriate significance test
To find an appropriate statistical test, the structure of the data should be considered. Before starting an analysis, one should ask the following questions:
How many dependent/independent variables are there?
What are the types of the variables?
Are the measurements in some way associated (i.e. matched)?
What is there besides significance?
Once you have found an appropriate test, you may want to look into topics that go beyond mere significance, such as:
How can I use effect sizes to describe the extent of an effect?
How can I use power analysis to identify the likelihood that a test detects an effect if it exists?
How can I interpret measurements using other quantities such as confidence intervals?
Posts on statistical testing
You can find answers to these questions (and more) in the following posts on statistical testing.
The means of quantitative measurements from two groups can be compared using Student’s t-test. To compare the means of measurements for more than two levels of a categorical variable, one-way ANOVA has to be used. Here, we’ll explore the parametric, one-way ANOVA test as well as the non-parametric version of the test, the Kruskal-Wallis test, which compares median values.
When planning statistical tests, it is important to think about the consequenes of type 1 and type 2 errors. Typically, type 1 errors are considered to be the worse type of error. While the rate of type 1 errors is limited by the significance level, the rate of type 2 errors depends on the statistical power of the test. Here, we discuss how the null hypothesis should be chosen and how the two types of errors are related.
So, you performed a test for significance and obtained a positive result. That’s great but it’s not time to celebrate yet. You may ask: Why? Isn’t a significant test result sufficient to show the existence of an effect? This statement, however, is not true for two reasons. First, a significant result only indicates the existence of an effect but doesn’t prove it. For example, at a significance level of 5%, an exact test will yield a false positive result in 5% of the cases. Second, a significant result does not necessarily make a statement about the magnitude of the effect. In this post, we’ll investigate the difference between statistical significance and the effect size, which describes the magnitude of an effect.
McNemar’s test is a non-parametric test for contingency tables that arise from paired measurements. In contrast to the chi-squared test, which is a test for independence, McNemar’s test is a test for symmetry (also called marginal homogeneity). Still, McNemar’s test is related to the chi-squared test because its test static also follows a chi-squared distribution.
In a previous post, I’ve contrasted two tests for pairs of measurements. Here, I’d like to show why it is important to choose a test that appropriately accounts for such dependent measurements.
Parametric tests are subject to assumptions about the properties of the data. For example, Student’s t-test is a well-known parametric test that assumes that sample means have a normal distribution. Due to the central limit theorem, the test can be also applied to measurements that are not normally distributed if the sample size is sufficient. Here, we will investigate the approximate number of samples that are necessary for the t-test to be valid.
One of the most common areas of statistical testing is testing for independence in contingency tables. In this post, I will show how contingency tables can be computed and I will introduce two popular tests on contingency tables: the chi-squared test and Fisher’s exact test.
In this post, we will explore tests for comparing two groups of dependent (i.e. paired) quantitative data: the Wilcoxon signed rank test and the paired Student’s t-test. The critical difference between these tests is that the test from Wilcoxon is a non-parametric test, while the t-test is a parametric test. In the following, we will explore the ramifications of this difference.