Need a holiday from data science? Then this page is for you because this category encompasses all the posts that are not directly associated with data science. Until now, these posts have mostly dealt with blogging with Hugo but let’s see what the future brings. Anyway, I don’t plan to stray too far away from the intended focus of the blog, so there should never be too many posts under this category.
In this post, I want to share how Python can be used to automate the documentation of machine-learning (ML) experiments using AsciiDoc.
The search for the best-performing ML model is an empirical process, which involves fitting models with differing parameters and evaluating their predictive performance. Only after a multitude (e.g. hundreds or thousands) of models have been evaluated, is it possible confidently proclaim that a suitable model has been identified. The major challenge of running vast numbers of experiments is that they are time- and compute-intensive because results usually have to be delivered within a certain time frame (e.
GPUs are an important asset for machine learning projects. If you are a researcher that is in dire need of GPUs, then look no further than HOSTKEY's GPU grant program.
Are you a researcher in data science? Are you in desparate need for GPU ressources for your next project? Then you should know that a GPU server may be just around the corner.
HOSTKEY is currently hosting a competition where you can win a grant for free GPU ressources. The competition is open to all researchers in the data science sphere.
Application Criteria for the Grant Program If you want to apply, you have to send the following information:
Companies usually have firewalls in place, which ensure that the internal network is protected. To access the outside world, all traffic must be routed through a proxy. When you are using the standard operating system (typically Windows), you are automatically authenticated with this proxy.
However, when you are using a non-standard operating system (e.g. through a virtual machine running Linux), you are not automatically authenticated with the company’s proxy. The sad result: you won’t be able to access the internet out of the box.
When I started working in the IT sector, I was impressed by the large number of different roles that exist and it took me quite a bit of time to understand their individual responsibilities. That is why I thought it would be nice to share my understanding of the most common roles you will encounter in IT projects.
You should definitely read this post if you are thinking about applying for position in the information technology sector but are unsure which one is the right fit for you or if you’re already working in IT and want to improve your understanding of other roles.
As you probably know, I’m a big fan of Staticman’s approach to enable dynamic content on static web sites. When I introduced comments on this blog, things quickly got out of hand: Each day, I would receive roughly five comments that were posted by bots.
Spam comments as pull requests in GitHub
Manually approving each post quickly became a nuisance, which is why I deactivated Staticman again after some time.
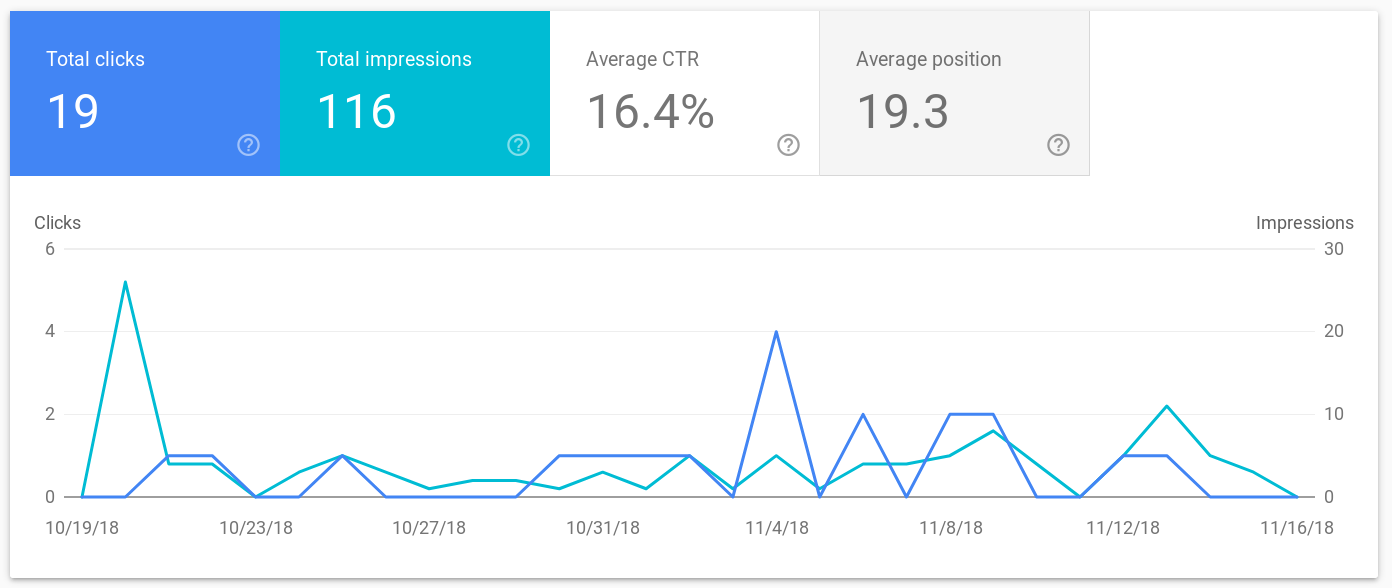
By now, datascienceblog.net already exists for one month, with the first post dating back to the 16th of October, 2018. I would like to use this opportunity to reflect on how the blog has developed since its inception.
Content I am quite happy with the amount of content I could produce over the last couple of weeks. Especially when starting a blog, high-quality content is the most important criterion for developing a user base.
In a previous post, I have described how to set up your own Staticman instance and use it to run a commenting system. Since Staticman is not limited to bringing comments to static sites, I decided to implement polls with Staticman as well.
Overview In order to get polls working, the following steps need to be followed:
Adjust your Staticman configuration to include a configuration for polls Create two subfolders in your data folder: one for storing the votes and one for setting up the polls Implement the Hugo template logic for the polls in your partials Implement JavaScript/CSS to allow for participating in the poll and viewing the results Staticman configuration Configuring Staticman for polls is relatively straight-forward.
Comments are an important aspect of many websites, particularly blogs, whose success depends on their ability to create communities. However, including comments is inherently more difficult for static websites than for dynamic websites (e.g. managed through Wordpress). With Hugo, comments can be easily integrated via Disqus. The disadvantage, however, is that foreign JavaScript code needs to be executed and that the comments are not part of the page itself. Here, I will
explain how comments can be integrated into a web page using Staticman.
Taxonomies in Hugo are a great way to structure information provided by a blog. For search engine optimization (SEO) purposes, however, the existence of duplicate content on a site can be a problem. If you think this is the case for your site, then you can use the noindex meta tag for all of the taxonomy sites that do not provide unique content. This post shows you how to get it done.