Besides interpretability, predictive performance is the most important property of machine learning models. Here, I provide an overview of available performance measures and discuss under which circumstances they are appropriate.
Performance measures for regression
For regression, the most popular performance measures are R squared and the root mean squared error (RMSE). \(R^2\) has the advantage that it is typically in the interval \([0,1]\), which makes it more interpretable than the RMSE, whose value is on the scale of the outcome.
Performance measures for classification
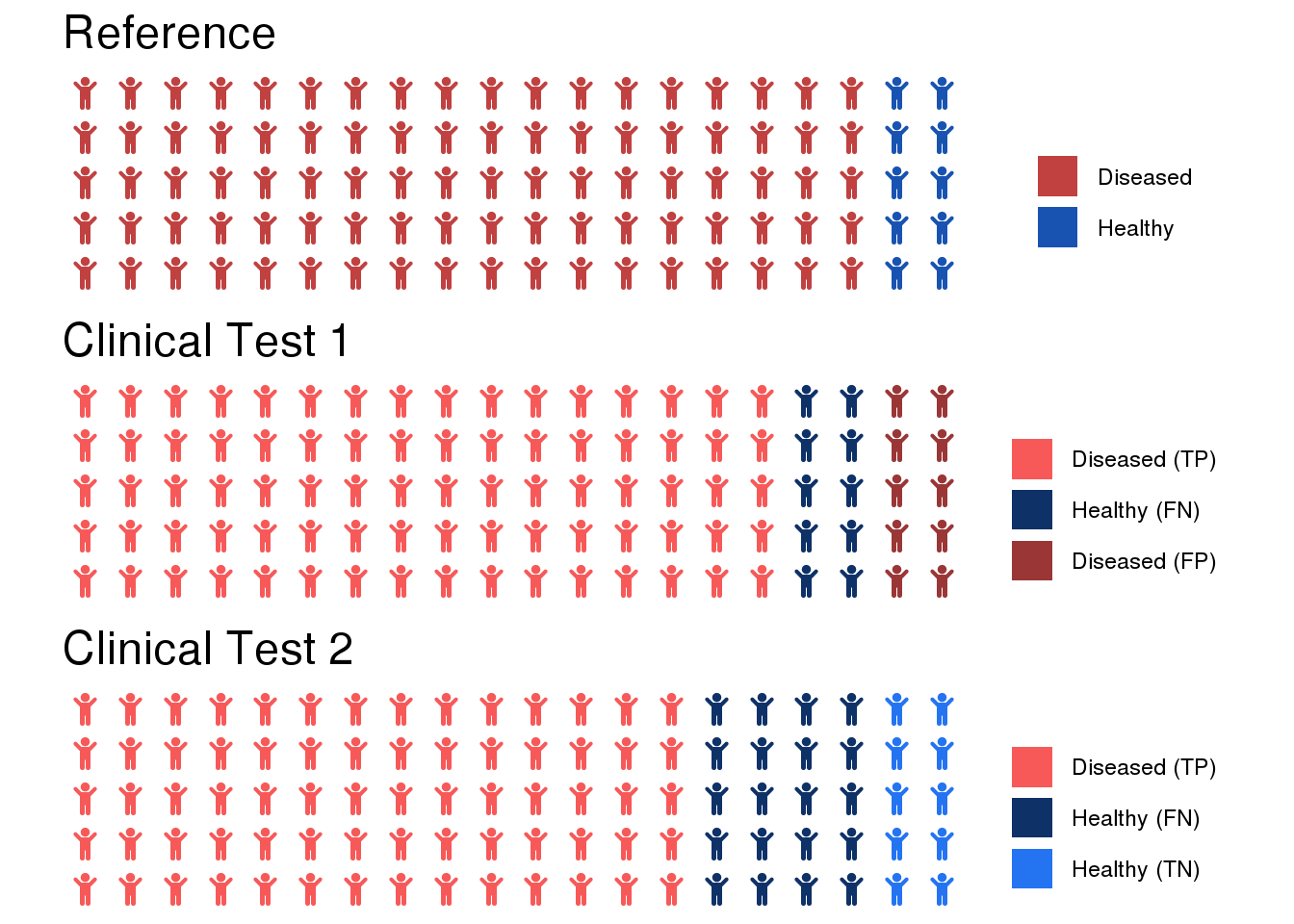
The performance of models for binary classification is evaluated on the basis of confusion matrices, which indicate true positives, false positives, true negatives, and false negatives. Based on these quantities, the performance measures of sensitivity and specificity (balanced accuracy) are derived.
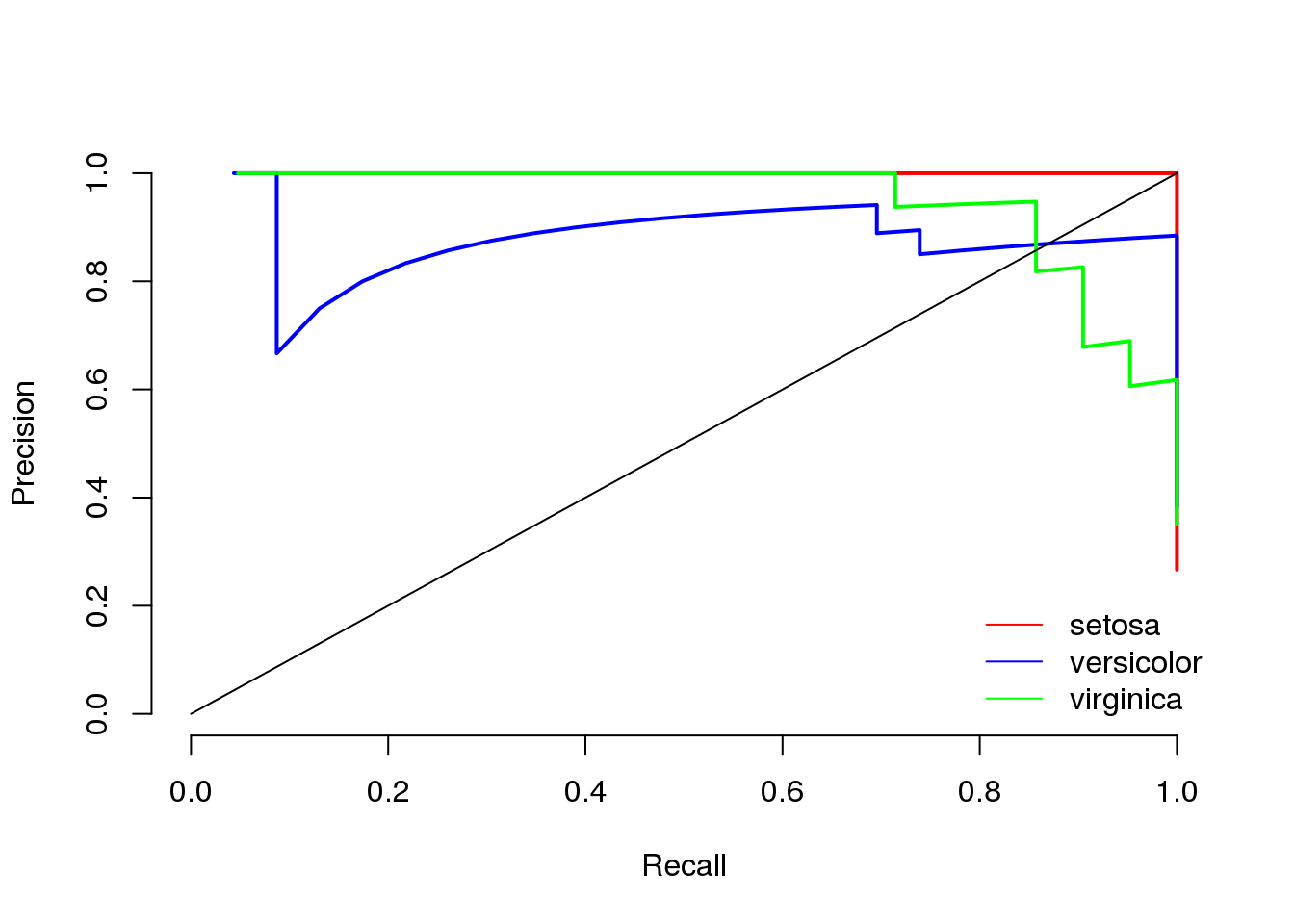
In specific circumstances, it is worthwhile to consider recall and precision (the F1 score) rather than sensitivity and specificity.
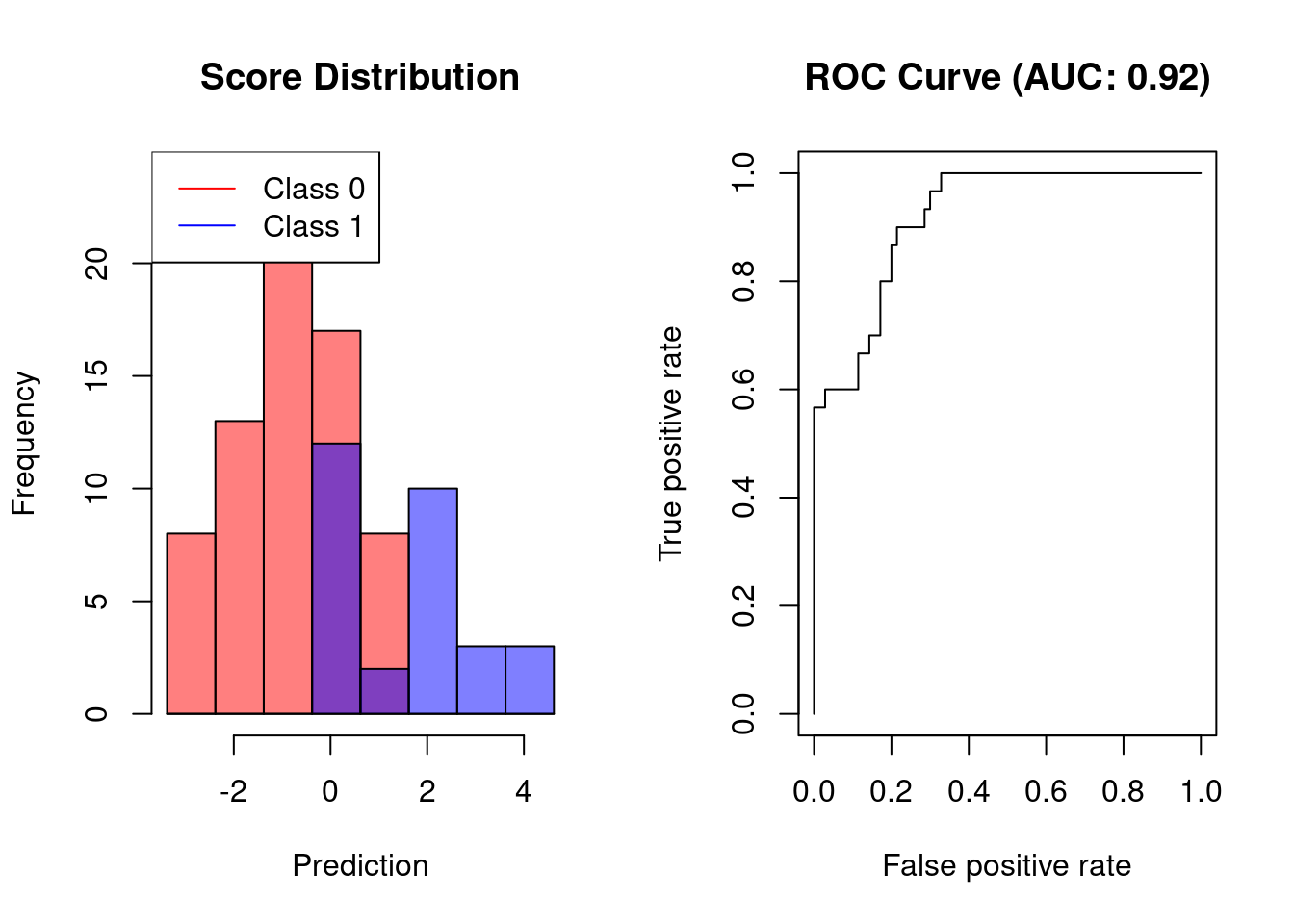
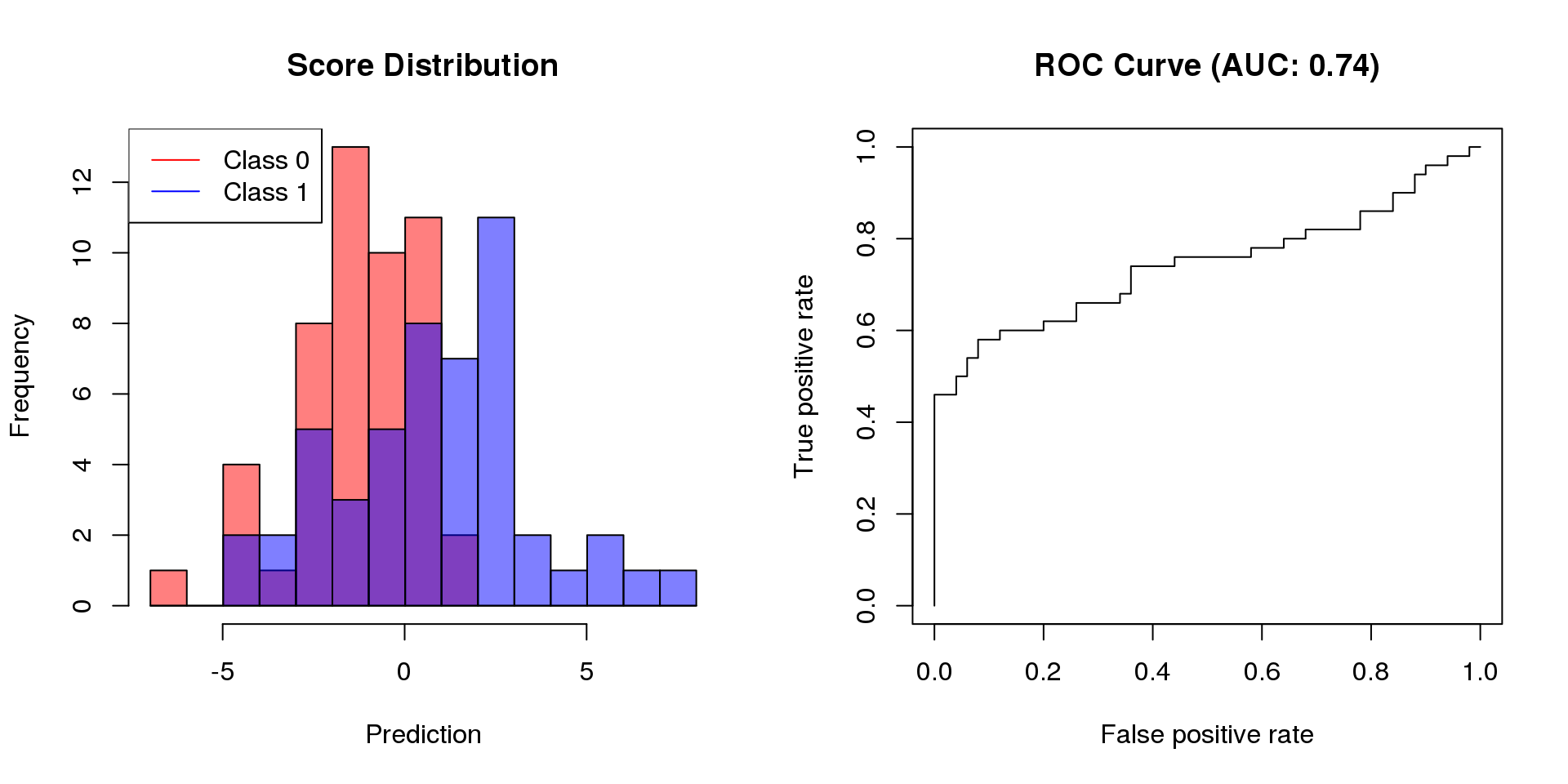
For scoring classifiers, the area under the receiver operating characterstic curve (AUC) can be used to measure the sensitivity-specificity tradeoff for different classification thresholds.
Performance measures for feature selection
When comparing models with different number of features, model complexity should be taken into account through measures such as the adjusted \(R^2\) or the Akaike information criterion (AIC). Alternatively, to curb overfitting, model performance can be determined on an independent test set (e.g. via cross validation).
Posts about performance measures
The following posts discuss performance leasures for supervised learning and how they can be computed using R.
Receiver operating characteristic (ROC) curves are probably the most commonly used measure for evaluating the predictive performance of scoring classifiers.
The confusion matrix of a classifier that predicts a positive class (+1) and a negative class (-1) has the following structure:
Prediction/Reference Class +1 -1 +1 TP FP -1 FN TN Here, TP indicates the number of true positives (model predicts positive class correctly), FP indicates the number of false positives (model incorrectly predicts positive class), FN indicates the number of false negatives (model incorrectly predicts negative class), and TN indicates the number of true negatives (model correctly predicts negative class).
For classification problems, classifier performance is typically defined according to the confusion matrix associated with the classifier. Based on the entries of the matrix, it is possible to compute sensitivity (recall), specificity, and precision. For a single cutoff, these quantities lead to balanced accuracy (sensitivity and specificity) or to the F1-score (recall and precision). For evaluate a scoring classifier at multiple cutoffs, these quantities can be used to determine the area under the ROC curve (AUC) or the area under the precision-recall curve (AUCPR).
In a recent post, I have discussed performance measures for model selection. This time, I write about a related topic: performance measures that are suitable for selecting models when performing feature selection. Since feature selection is concerned with reducing the number of dependent variables, suitable performance measures evaluate the trade-off between the number of features, \(p\), and the fit of the model.
Performance measures for regression Mean squared error (MSE) and \(R^2\) are unsuited for comparing models during feature selection.
Recently, I have introduced sensitivity and specificity as performance measures for model selection. Besides these measures, there is also the notion of recall and precision. Precision and recall originate from information retrieval but are also used in machine learning settings. However, the use of precision and recall can be problematic in some situations. In this post, I discuss the shortcomings of recall and precision and show why sensitivity and specificity are generally more useful.
There are several performance measures for describing the quality of a machine learning model. However, the question is, which is the right measure for which problem? Here, I discuss the most important performance measures for selecting regression and classification models. Note that the performance measures introduced here should not be used for feature selection as they do not take model complexity into account.
Performance measures for regression For models that are based on the same set of features, RMSE and \(R^2\) are typically used for model selection.