I was recently alerted because my Bioconductor package openPrimeR was failing the automated package tests.
The reason for this is that the Bioconductor team has decided to set a new environment variable when testing the packages.
In reinforcement learning, we are interested in identifying a policy that maximizes the obtained reward. Assuming a perfect model of the environment as a Markov decision process (MDPs), we can apply dynamic programming methods to solve reinforcement learning problems.
In this post, I present three dynamic programming algorithms that can be used in the context of MDPs. To make these concepts more understandable, I implemented the algorithms in the context of a gridworld, which is a popular example for demonstrating reinforcement learning.
For designing object-oriented software, five principles have emerged over the years. These principles are summarized by the acronym SOLID, which stands for:
S: The single-responsibility principle O: The open-closed principle L: The Liskov substitution principle I: The interface segregation principle D The dependency inversion principle In this post, I aim to give a succinct summary of the principles together with practical examples on how to apply them.
A PhD is not only a test of professional aptitude but also a test of character. Looking back at my time as a PhD student, I can say that it has been a taxing but equally rewarding time that I wouldn’t exchange for anything in the world. Doing a PhD has not only improved my scientific and technical understanding but has also strengthened my character.
In this post I describe five characteristics that I found to be helpful in successfully completing my PhD.
As you probably know, I’m a big fan of Staticman’s approach to enable dynamic content on static web sites. When I introduced comments on this blog, things quickly got out of hand: Each day, I would receive roughly five comments that were posted by bots.
Spam comments as pull requests in GitHub
Manually approving each post quickly became a nuisance, which is why I deactivated Staticman again after some time.
Learn about the greatest differences between a data science role in academia and a software engineering role in industry. How to prepare for the transition?
Having recently transitioned from academia to industry, I’d like to share what I found are the greatest differences between working in industry and academia. Since this article is based on my personal experiences, I would first like introduce my respective roles in research and in industry. After that, I will summarize the main differences between industry and academia. Finally, I offer some pieces of advice regarding how to prepare for an industry job when transitioning from academia.
Having obtained both a Bachelor’s and a Master’s degree in bioinformatics, I would like to describe how I experienced studying bioinformatics. Moreover, I would like to discuss whether it was worth studying in the first place, and, finally, to offer some advice to prospective students and graduates.
What is Bioinformatics? Bioinformatics is an interdisciplinary field that is concerned with developing and applying methods from computer science on biological problems.
During my time as a PhD student I have developed software in the academic setting. At that time I was already under the impression that my work would probably not meet industry standards. Having recently transitioned to an industry job, I quickly realized how coding in academia is different from coding in industry. This post summarizes the main differences between the two fields and extrapolates what coders in academia can learn from industry.
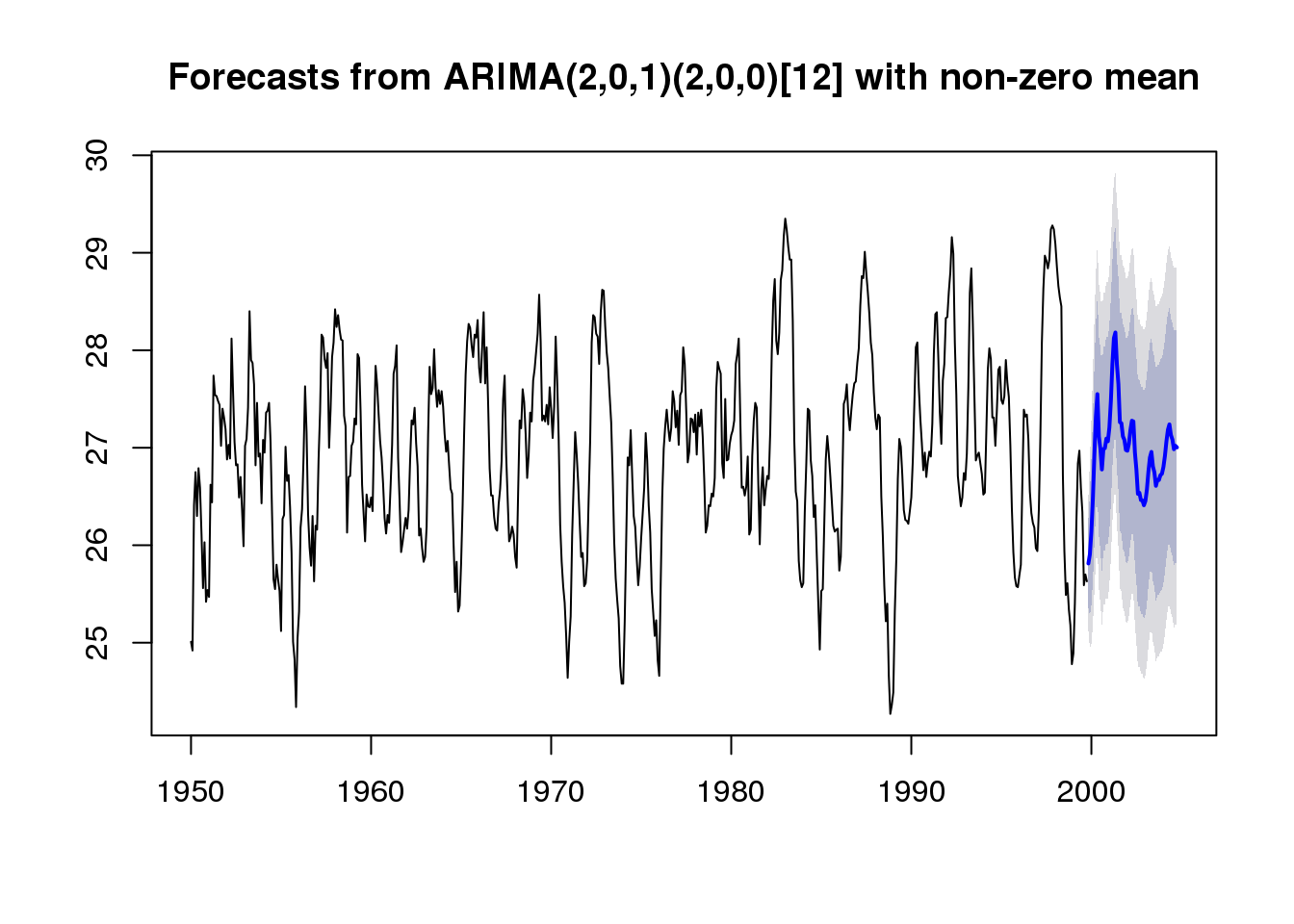
Forecasting is concerned with making predictions about future observations by relying on past measurements. In this article, I will give an introduction how ARMA, ARIMA (Box-Jenkins), SARIMA, and ARIMAX models can be used for forecasting given time-series data.
Preliminaries Before we can talk about models for time-series data, we have to introduce two concepts.
The backshift operator Given the time series \(y = \{y_1, y_2, \ldots \}\), the backshift operator (also called lag operator) is defined as
In supervised learning, we are often concerned with prediction. However, there is also the concept of forecasting. Here, I will discuss the differences between the two concepts so that we can answer the question why weather forecasting is not called weather prediction.
Predicion and forecasting Prediction is concerned with estimating the outcomes for unseen data. For this purpose, you fit a model to a training data set, which results in an estimator \(\hat{f}(x)\) that can make predictions for new samples \(x\).