Preventing Spam Using ReCAPTCHA and Staticman
As you probably know, I’m a big fan of Staticman’s approach to enable dynamic content on static web sites. When I introduced comments on this blog, things quickly got out of hand: Each day, I would receive roughly five comments that were posted by bots.
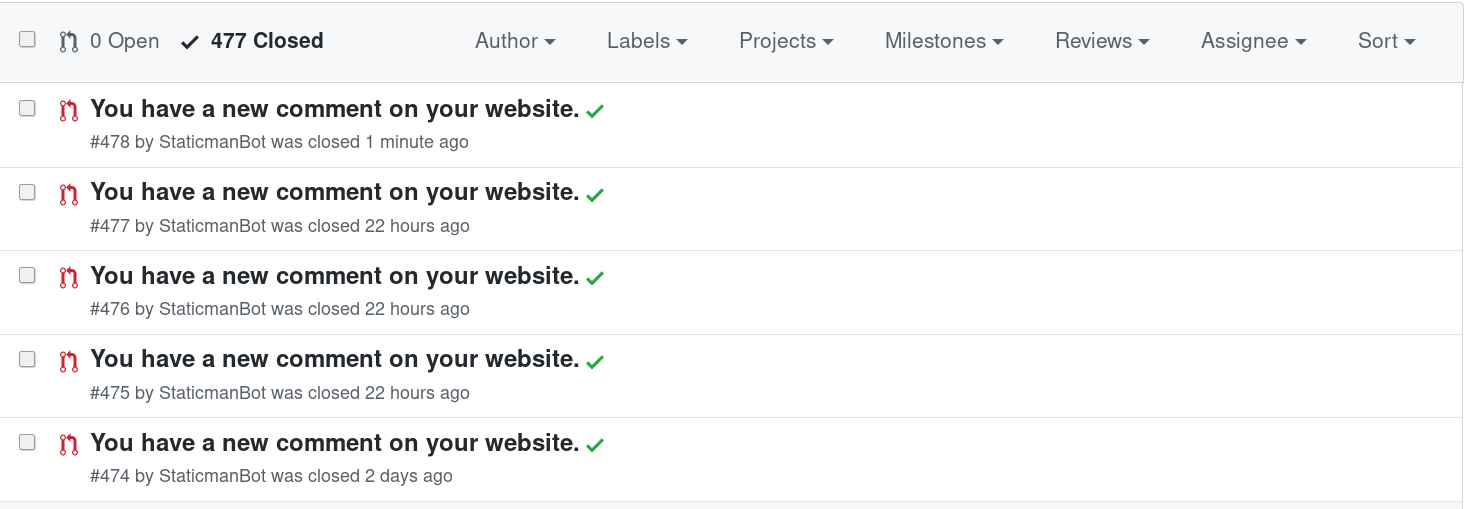
Spam comments as pull requests in GitHub
Manually approving each post quickly became a nuisance, which is why I deactivated Staticman again after some time. Some time later, I decided to install a standard solution for dealing with spam - Google’s ReCAPTCHA approach. Setting up ReCAPTCHA with Staticman, however, didn’t go as smoothly as expected. In this post, I describe my journey to get ReCAPTCHA working with Staticman and what I learned in the process.
Introduction to ReCAPTCHA
ReCAPTCHA aims at differentiating between human users and bots. It is most often used in the context of forms, which are intended as a form of communication between human users. However, there are also people that exploit forms for the purpose of spamming. These people don’t spam form fields by hand but instead use automated approaches, so called bots, that automatically fill in the forms and then submit it. Bots are great for spammers but a real nuisance for web site owners like me who would like to offer a nice platform for people to hang out where one is not constantly advised to buy ominous drugs or invest in bitcoin.
When you register your site with ReCAPTCHA, you will receive two tokens. A public site key, which is used for client-side identification and a secret token, which is intended for server-side verification. The approach that ReCAPTCHA uses to identify bots evolved over the years.
ReCAPTCHA v1
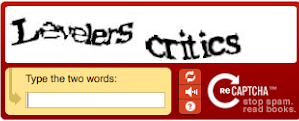
Users are presented by visually distorted words and have to transcribe them. Usability was low because it was tedious to get the CAPTCHA right. Moreover, smart bots could easily overcome the challenge.
ReCAPTCHA v2
With ReCAPTCHA v2, users are presented by a checkmark, which allows for verifying that one is not a robot.

After pressing the checkmark, the system assesses whether the interaction was natural or not. If it wasn’t, then the user has to select the appropriate elements from a grid.

ReCAPTCHA v2 greatly improved the user experience over v1 because humans usually just have to check the box and do not have to solve a riddle.
ReCAPTCHA v3:
ReCAPTCHA v3 revolutionized the the ReCAPTCHA system because this is the first version where no challenge is posed to the client. Instead, Google relies solely on their vast amount of user data in order to evaluate the client’s behavior.
The output of these evaluations is a risk score, which ranges from from 0 (definitely a bot) to 1 (definitely human). With this, user experience is as smooth as possible. Moreover, website owners can regulate the stringency of spam protection by selecting an appropriate cutoff on the computed score. For example, one could use a stringent cutoff for account creation but a less stringent cutoff for registering for a newsletter.
How not to Implement ReCAPTCHA
Now that we share a common understanding about ReCAPTCHA, let’s talk about how not to implement ReCAPTCHA. To solve my spam problems, I tried to implement a solution using ReCAPTCHA v2. After registering my blog at ReCAPTCHA, I stumbled upon a Edouardo Bouca’s GitHub repo where he explains how Staticman can be setup using ReCAPTCHA v2. At this point, I thought all my problems would easily be solved. However, for some reason, I couldn’t get the setup to work. That’s where my odyssey into ReCAPTCHA verification started.
The first thing I investigated was whether I could verify the ReCAPTCHA on the client-side. For this purpose, I implemented a JavaScript function that would return true if the ReCAPTCHA challenge was solved correctly and false otherwise:
function validateRecaptcha() {
var response = grecaptcha.getResponse();
if (response.length === 0) {
console.log("recaptcha not verified")
return false;
} else {
alert("recaptcha validated");
return true;
}
}To integrate the validation function into the form submission of the commenting system,
I used the onSubmit event. Only if the onSubmit event evaluates to true will the action of the form be triggered:
<form class="post-comment" method="POST" action="{{ .Site.Params.staticman.comments_api }}" onsubmit="return validateRecaptcha();">However, after some further research, I realized that there was something fundamentally wrong with this approach. What could be the problem? Well, the verification function I implemented actually never checks the ReCAPTCHA response token using the secret key provided by ReCAPTCHA. As such, the verification function always returns true, as long as any ReCAPTCHA token is generated - the challenge doesn’t have to be solved correctly.
In general, client-side verification of ReCAPTCHA tokens should never be performed because this would require making the secret ReCAPTCHA key public, which should never be done.That’s because if the secret is publicly available via the client-side code, anyone could verify the generated tokens for your site. So, you should definitely not verify ReCAPTCHAs on the client-side.
Getting Closer to a Correct Implementation
After failing to get ReCAPTCHA working for such a long time, I was close to giving up. However, I was even more frustrated about not being able to get something simple like this to work, which is why I made another attempt to get it right.
What became clear to me was that I would need to have a service for verifying the ReCAPTCHA response on the server side. Since I’m hosting a static site, I don’t have a server at my disposal. Luckily, nowadays, cloud computing is all the rage, which is why it’s relatively easy to set up some serverless code for verifying the ReCAPTCHA response. In the following, I will show you how to setup a service for verifying ReCAPTCHA responses on AWS.
When I investigated ReCAPTCHA investigation using AWS, I found some lambda code from lighthacker in the public repository. This code is based on Node.js and utilizes Express to offer a REST API whose endpoint is verify, which takes the token that is generated by ReCAPTCHA as a parameter. The service then performs the verification through Google’s siteverify API.
Although the implementation sets Access-Control-Allow-Origin to an asterisk, I still encountered problems with CORS when I copied the AWS lambda code and deployed it. I tried many things such as adapting the CORS capabilities in the AWS API gateway but nothing worked, so I decided to redeploy the code rather than simply copying the application’s setup in AWS. For this purpose, I performed the following steps:
- Download the Node.js project
- Install the dependencies using
npm install - Verify the implementation (including CORS) by running the API using
node app.jsand posting requests via Postman
To do the AWS setup on the command line, I used the serverless approach described in Marc Logemann’s Medium post. I first installed serverless via npm install -g serverless and then created a serverless.yml file with the following content:
service: recaptcha-less
provider:
name: aws
runtime: nodejs12.x
stage: dev
region: us-east-1
memorySize: 128
functions:
app:
handler: app/index.handler
events:
- http:
path: /
method: ANY
cors: true
Then, I just ran serverless config credentials -p aws -k {personalKey} -s {secretToken}, followed by serverless deploy in order to configure the deployment on AWS. After the API was running on AWS, I implemented a client-side function for interacting with the API:
async function validateRecaptcha() {
// read hidden form fields
var token = document.getElementById("gRecaptchaResponse").value;
var verify_api = document.getElementById("verify_url").value;
// call verification API using captcha token
const response = await fetch(verify_api+token, {
headers: {
'Accept': 'application/json',
'Content-Type': 'application/json'
},
mode: 'cors',
method: 'GET'
})
var result = await response.json();
return (result.success == "true" && result.score >= 0.6);
}The function only returns true if the server-side ReCAPTCHA verification did not yield an error (success is set to true) and the score is sufficiently high.
When I deployed this system on my blog, something unexpected happened. While I definitely received less spam than before, I still received bursts of spam at specific times. Since the ReCAPTCHA verification was correctly implemented, I quickly identified the problem: the Staticman API was not protected by the ReCAPTCHA: I had spent all this time barricading the front door (i.e. the commenting system on the blog) but I had left the back door white open because the Staticman API was still publicly accessible without any spam protection.
Moreover, I also wasn’t really happy with using ReCAPTCHA v3 because it takes away human control: if your score is too low, you do not get a chance to prove that you’re human. I’d prefer an invisible CAPTCHA where you can still prove your humanity rather than being simply blocked but it seems that something like this is currently not available, so ReCAPTCHA v2 is the better alternative.
Implementing Spam Protection for Staticman
Having reckoned that I needed to protect my instance of the the Staticman API rather than the commenting system itself, I investigated solutions for this. Since I didn’t get ReCAPTCHA to work with Staticman the first time around, I configured Akismet with Staticman, which showed the expected result directly.
Again, I wasn’t really happy with this solution because now I was using two services that serve the same purpose: ReCAPTCHA v3 on the website and Akismet on the Staticman API. So, to clean the mess up, I decided to give the Staticman ReCAPTCHA integration another shot. Again, I followed Edouardo’s guide and this time I got it working - probably because I had previously entered incorrect data into the Staticman configuration.
So, with all the work done, I am now simply using Staticman’s ReCAPTCHA v2 verification rather than the custom ReCAPTCHA v3 implementation I used before. This way, the API cannot be accessed with a correct ReCAPTCHA v2 token.
Lessons Learned
Staticman’s ReCAPTCHA verification works well - if you should have problems getting your configuration to work, make sure you have entered all the details correctly. Of course, there are also other methods but those are time-intensive and may still leave the API endpoint unprotected.
My general learnings from working with the ReCAPTCHA system are as follows:
- Do not try to verify ReCAPTCHAs on the client-side
- Spammers are more intelligent than one would expect: they quickly figure out how to abuse unprotected APIs for their purposes
- It’s useless to protect your web frontend using ReCAPTCHA if the API you are relying on is not protected using ReCAPTCHA or some other form of spam protection
- ReCAPTCHA v3 may be more user friendly than ReCAPTCHA v2 but undermines free choice
If you have any questions about the use of ReCAPTCHA with Staticman or ReCAPTCHA in general, don’t hesitate to contact me.



Comments
Ruann
26 Mar 20 11:19 UTC
Hi There,
Thanks for making this article,
I’m in the same predicament you mentioned here but I’m not using staticman. I’ve got a s3 static host on AWS I want to use so no server side scripting.
Recaptcha seems very difficult to implement like this. The amazon examples are pointless because they don’t do anything.
All I want is to use a plain html page that checks the user has filled in what they are supposed to and checked the box or do it invisibly and then use the response from google to allow or disallow the form submit.
Your article is great but i’m just trying to integrate what code you’ve shared with an actual form as well as the script. I don’t know JS and ajax so well so I’m going in circles !
Any advice or assistance would be HUGELY appreciated. Thanks
Matthias
26 Mar 20 11:56 UTC
Hi there, if you aren’t using Staticman then I’d recommend just hosting your own recaptcha verification service on AWS to get the job done as described in the section “Getting Closer to a Correct Implementation”. Since there is an implementation available that works well, you don’t need to know a lot of Javascript to integrate it into your site so I think you should be fine with this solution.
Short summary of the steps:
Ruann
31 Mar 20 17:36 UTC
Thanks for you clear and well informed reply I’ve managed to get it working now.
Just for reference for any future person in my situation: I ended up: -Adding some extra code to the Lamda service to verify the captcha response -I incorporated the response in a Javascript that first verifies all the inputs to the form a user enters, and once those are all in order or OK, checks the token or recaptcha has been submitted or checked -when it is checked , the response from the google api is used to allow the form to be submitted.
It seems to be working now so thanks again for the assistance.