Behind the Scenes: The First Month of datascienceblog.net
By now, datascienceblog.net already exists for one month, with the first post dating back to the 16th of October, 2018. I would like to use this opportunity to reflect on how the blog has developed since its inception.
Content
I am quite happy with the amount of content I could produce over the last couple of weeks. Especially when starting a blog, high-quality content is the most important criterion for developing a user base. This is why I focused my time mostly on writing. With regard to the topics, I tried to cover as many aspects of data science as possible in order to showcase that this blog tries to give a generalist view on data science as a discipline, rather than narrowing down the content on a single aspect.
So far, the main categories of the blog are basic statistics, data visualization, machine learning, other, and statistical tests. I will probably introduce a programming category in the future because I think that this is one of the overlooked aspects in data science.
Features of the blog
Regarding the features of the blog, I spent quite some time on the commenting system and on the polls. Initially, the commenting system was provided by Disqus but I have switched to Staticman in the meantime. So far, I am really happy with this solution. The only disadvantage of the system is that I am using a free Heroku dyno, so you have to show some patience when the dyno is currently sleeping. Since the cheapest dyno that never sleeps is currently 7$ a month, which is quite expensive, I am not sure if I will switch to the paid model in the future. The polls are also powered by Staticman. I plan to frequently update the polls and include the outcomes in my blog posts.
I was also concerned with removing some HTML errors in the blog’s code, which I found using the W3C markup validation service.
Search engine optimization
Since taxonomy pages such as the category and tag pages lead to a lot of duplicate content, I decided to exclude these pages from search robot indexing. It turned out that this was not the best way to go because the taxonomy pages actually attract a lot of search traffic. Thus, instead of excluding these pages, I decided to improve upon these pages to reduce the issue of duplicate content. The categories and tags pages now give much better overviews of the discussed topics than before, so the effort was definitely worth it. I would recommend updating the taxonomy pages every week or so, in order to keep them up to date. Although creating these pages takes up a considerable amount of time initially, it is definitely worth it.
To generate backlinks to the blog, I included links to the blog on other sites of mine. I also recommended some posts on sites such as LinkedIn, DataTau, and Quora. I also tested syndicating some posts on Medium. However, I found that if you do not have a lot of followers there and do not belong to a publication, the number of readers is extremely small, so I am not sure if I will continue posting there. I also registered the blog on three aggregators for data science and R: Analisted, R-bloggers, and Data science blogs reader. Since the blog is based on blogdown, I had it included at Awesome Blogdown and joined the Rbind community, for which I wrote a post on my experiences with blogging and data science. With these measures, the current PageRank of the blog is already at 1 but I hope it will soon increase further.
Traffic
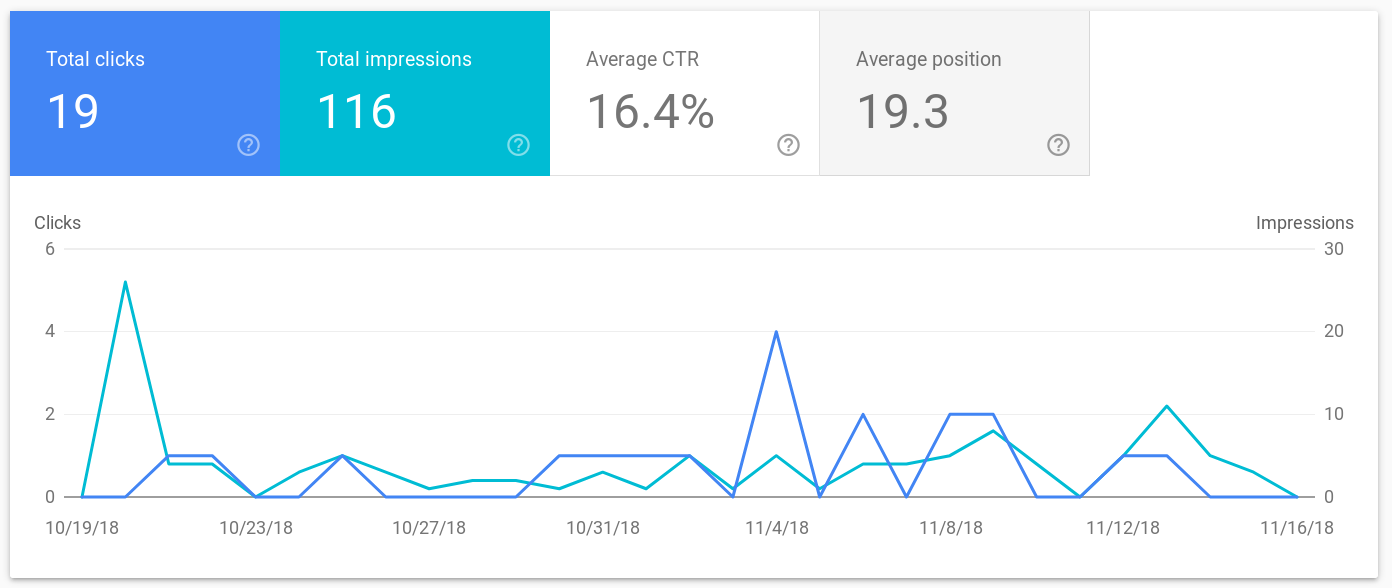
I am not using Google Analytics, so I cannot write anything about the traffic. I am, however, using Google Search Console, which is why I can report on Google search traffic. The blog was indexed very quickly, only four days after the first post. Using the Search Console probably helped with that. Interestingly, the number of search impressions was the highest on the day that the blog was indexed and was drastically lower the following days. Maybe this is because Google gives fresh content a bonus, which is removed if the click rate is low.
Anyways, most of the days, the number of impressions was in the single digits. The largest number of clicks on a single day was 4. Overall, these results are not so surprising, considering that the blog is so new. Moreover, I can already state that the results for the new month seem more promising, which is probably the results of the SEO measures I performed over the last weeks.



Comments
There aren't any comments yet. Be the first to comment!