Tags
Python
software engineering
R for applications in data science
The R logo, licensed under CC-BY-SA 4.0. All posts with the R tag deal with applications of the statistical programming language R in the data science setting.
Posts about R
reinforcement-learning
Supervised Learning
Supervised learning is concerned with models for predicting the outcome for new data points.
Models for supervised learning The following supervised learning models are important:
Linear models: models that assume the existence of a linear relationship between the independent variables and the outcome. Support vector machines: models that deal with non-linear associations by transforming the data to another space via kernel functions. Neural networks: models that emulate the interaction of neurons in the nervous system.
Performance Measures
Besides interpretability, predictive performance is the most important property of machine learning models. Here, I provide an overview of available performance measures and discuss under which circumstances they are appropriate.
Performance measures for regression For regression, the most popular performance measures are R squared and the root mean squared error (RMSE). \(R^2\) has the advantage that it is typically in the interval \([0,1]\), which makes it more interpretable than the RMSE, whose value is on the scale of the outcome.
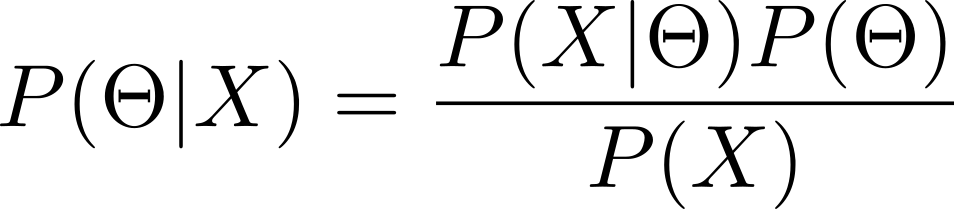
Bayesian methods
Bayesian methods make use of Bayes’ theorem to perform statistical inference. Bayes’ law states that a conditional probability can be decomposed in the following way:
\[P(A | B) = \frac{P(B|A) P(A)}{P(B)}\]
where \(A\) and \(B\) indicate two events. The following terms are assigned to each of the quantities:
\(P(A|B)\) is the posterior probability \(P(B|A)\) is the likelihood of \(B\) given \(A\) \(P(A)\) and \(P(B)\) are the marginal probabilities for \(A\) and \(B\), respectively In statistical modeling, another parameterization is typically used.
Linear Prediction Models
Linear prediction models assume that there is a linear relationship between the independent variables and the dependent variable. Therefore, these models exhibit high bias and low variance.
The high bias of these models is due to the assumption of nonlinearity. If this assumption does not sufficiently represent the data, then linear models will be inaccurate.
On the other hand, linear models also have a low variance. This means that if several linear models would be trained using different data, they would perform similarly on the same test data set.
Hugo
Hugo is a tool for creating static websites. How is this different from a dynamic website? you may be wondering. While a static website is delivered to clients in the same way that is stored, dynamic websites build pages using an application server. As a consequence, static and dynamic web pages have contrasting properties:
Criterion Static Dynamic Loading Times Fast Slow Required Expertise for Maintenance High Low Security High Potentially Low Potential for User Interaction Low High Let’s take a look at these aspects in more detail.

